Preamble

MongoDB Database – Having installed the DB, we can now add data to it. All data is stored in the DB in the BSON format, which is close to JSON, so we also need to enter data in this format.
And although we may not have a single collection at the moment, it is automatically created when we add data to it.
As mentioned earlier, the name of the collection is an arbitrary identifier consisting of no more than 128 different alphanumeric characters and an underscore.
At the same time, the name of the collection shall not start with the prefix system as it is reserved for internal collections (e.g. the collection system.users contains all database users). Also, the name shall not contain the dollar sign – $.
Three of its methods may be used to add to the collection:
- insertOne(): adds a single document
- insertMany(): adds several documents
- insert(): can add both one and several documents
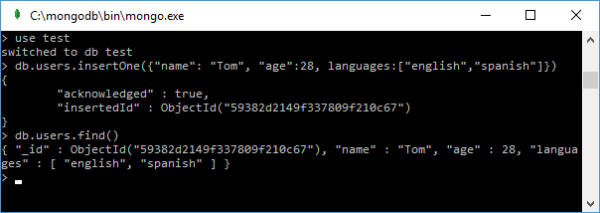
So, let’s add one document:
> db.users.insertOne({"name": "Tom", "age": 28, languages: ["english", "spanish"]})
The document represents a set of key-value pairs. In this case, the document to be added has three keys: name, age, languages, and each of them is matched with a certain value. For example, the key languages are matched with an array as a value.
There are some limitations when using key names:
- The symbol $ cannot be the first character in the key name.
- The key name cannot contain the character of a.
When adding data, if we have not explicitly provided a value for the field “_id” (i.e. a unique document identifier), it is generated automatically. But in principle we can set this identifier ourselves when adding data:
> db.users.insertOne({"_id": 123457, "name": "Tom", "age": 28, languages: ["english", "spanish"]})
It should be noted that the key names can be used in quotes, or maybe without quotes.
If added successfully, the ID of the added document will be displayed on the console.
And to make sure that the document is in dd, we output it using the find function.
> db.users.find()
To print in a more readable form let’s add the pretty() method:
db.users.find().pretty()
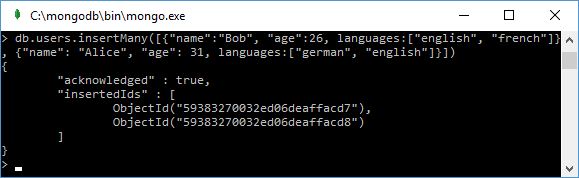
If we need to add some documents, we can use the insertMany() method:
db.users.insertMany([{"name": "Bob", "age": 26, languages: ["english", "frensh"]},
{"name": "Alice", "age": 31, languages:["german", "english"]}])
After adding, the console displays the IDs of the added documents:
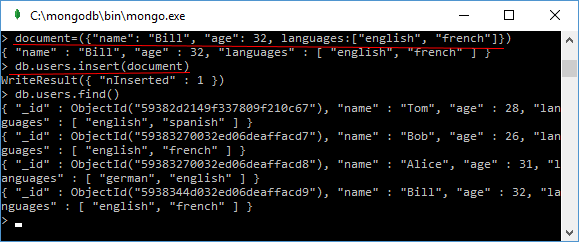
And the third method, insert(), demonstrates a more universal way to add documents. When it is called, the document to be added is also passed to it:
db.users.insert({"name": "Tom", "age": 28, languages: ["english", "spanish"]})
When it is called, the number of added entries is displayed on the console:
WriteResult({"nInserted" : 1 })
There is another way to add a document to the database, which includes two steps:
- the definition of the document (document = ( { … } )
- and the actual addition of the document:
If you want, you can also use db.users.find() function to verify that the document is in the database.
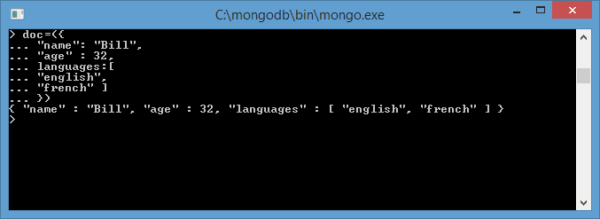
It may not be convenient for everyone to enter all key pairs and properties in one line. But the intelligent MongoDB interpreter based on javascript also allows you to enter multi-line commands.
If the expression is not finished (in terms of JavaScript), and you press Enter, the input of the next part of the expression will be automatically moved to the next line:
Loading data from a file
The data for the mongodb database can be defined in a regular text file, which is quite convenient because we can transfer or forward this file regardless of the mongodb database. For example, let’s define a users.js file somewhere on our hard drive with the following content:
db.users.insertMany([
{"name": "Alice", "age": 31, languages: ["english", "french"]},
{"name": "Lene", "age": 29, languages: ["english", "spanish"]},
{"name": "Kate", "age": 30, languages: ["german", "russian"]}
])
In other words, three documents are added to the user’s collection using the insertMany method.
To load a file into the current database, the load() function is used, in which the path to the file is passed as a parameter:
load("D:/users.js")
In this case, it is assumed that the file is located in the path “D:/users.js”.
MongoDB Tutorial: Insert Data Into MongoDB Database
Enteros
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
How Intelligent Database Analytics Transforms Performance in Modern Telecommunications Platforms
- 25 May 2026
- Database Performance Management
The telecommunications industry is experiencing one of the most significant digital transformations in its history. With the rapid expansion of 5G networks, IoT ecosystems, cloud-native infrastructure, edge computing, and real-time digital services, telecom providers are managing unprecedented volumes of data and operational complexity. Modern telecommunications platforms must deliver seamless connectivity, ultra-low latency, uninterrupted service availability, … Continue reading “How Intelligent Database Analytics Transforms Performance in Modern Telecommunications Platforms”
Improving SaaS Platform Reliability and Performance with Advanced Database Monitoring
Modern SaaS platforms operate in an environment where speed, uptime, scalability, and user experience directly impact business growth. Whether it is a CRM platform, collaboration tool, fintech application, healthcare system, or e-commerce SaaS solution, database performance remains the foundation of every digital interaction. As SaaS ecosystems expand across hybrid and multi-cloud infrastructures, maintaining consistent database … Continue reading “Improving SaaS Platform Reliability and Performance with Advanced Database Monitoring”
How to Reduce Operational Complexity with Enteros Database Optimization and Cloud Financial Intelligence
- 24 May 2026
- Database Performance Management
Introduction Modern enterprises are operating in increasingly complex digital environments driven by cloud computing, artificial intelligence, real-time analytics, distributed applications, and rapidly growing data ecosystems. Organizations across industries rely heavily on cloud-native platforms and database-driven applications to support scalability, operational agility, and customer experiences. Today’s technology ecosystems support: Cloud infrastructures SaaS applications AI and machine … Continue reading “How to Reduce Operational Complexity with Enteros Database Optimization and Cloud Financial Intelligence”
How to Improve Retail Cloud Efficiency with Enteros Database Software and Infrastructure Intelligence
Introduction The retail industry is rapidly transforming as organizations accelerate digital commerce initiatives, modernize customer engagement platforms, and expand cloud-based infrastructures. Retailers today operate highly connected ecosystems involving ecommerce platforms, supply chain systems, customer analytics applications, payment processing environments, and omnichannel retail experiences. Modern retail organizations rely heavily on cloud technologies to support: Ecommerce platforms … Continue reading “How to Improve Retail Cloud Efficiency with Enteros Database Software and Infrastructure Intelligence”